[ad_1]
Data preparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes. With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization from a single visual interface.
In this post, we explore the latest features of SageMaker Data Wrangler that are specifically designed to improve the operational experience. We delve into the support of Simple Storage Service (Amazon S3) manifest files, inference artifacts in an interactive data flow, and the seamless integration with JSON (JavaScript Object Notation) format for inference, highlighting how these enhancements make data preparation easier and more efficient.
Introducing new features
In this section, we discuss the SageMaker Data Wrangler’s new features for optimal data preparation.
S3 manifest file support with SageMaker Autopilot for ML inference
SageMaker Data Wrangler enables a unified data preparation and model training experience with Amazon SageMaker Autopilot in just a few clicks. You can use SageMaker Autopilot to automatically train, tune, and deploy models on the data that you’ve transformed in your data flow.
This experience is now further simplified with S3 manifest file support. An S3 manifest file is a text file that lists the objects (files) stored in an S3 bucket. If your exported dataset in SageMaker Data Wrangler is quite big and split into multiple-part data files in Amazon S3, now SageMaker Data Wrangler will automatically create a manifest file in S3 representing all these data files. This generated manifest file can now be used with the SageMaker Autopilot UI in SageMaker Data Wrangler to pick up all the partitioned data for training.
Before this feature launch, when using SageMaker Autopilot models trained on prepared data from SageMaker Data Wrangler, you could only choose one data file, which might not represent the entire dataset, especially if the dataset is very large. With this new manifest file experience, you’re not limited to a subset of your dataset. You can build an ML model with SageMaker Autopilot representing all your data using the manifest file and use that for your ML inference and production deployment. This feature enhances operational efficiency by simplifying training ML models with SageMaker Autopilot and streamlining data processing workflows.
Added support for inference flow in generated artifacts
Customers want to take the data transformations they’ve applied to their model training data, such as one-hot encoding, PCA, and impute missing values, and apply those data transformations to real-time inference or batch inference in production. To do so, you must have a SageMaker Data Wrangler inference artifact, which is consumed by a SageMaker model.
Previously, inference artifacts could only be generated from the UI when exporting to SageMaker Autopilot training or exporting an inference pipeline notebook. This didn’t provide flexibility if you wanted to take your SageMaker Data Wrangler flows outside of the Amazon SageMaker Studio environment. Now, you can generate an inference artifact for any compatible flow file through a SageMaker Data Wrangler processing job. This enables programmatic, end-to-end MLOps with SageMaker Data Wrangler flows for code-first MLOps personas, as well as an intuitive, no-code path to get an inference artifact by creating a job from the UI.
Streamlining data preparation
JSON has become a widely adopted format for data exchange in modern data ecosystems. SageMaker Data Wrangler’s integration with JSON format allows you to seamlessly handle JSON data for transformation and cleaning. By providing native support for JSON, SageMaker Data Wrangler simplifies the process of working with structured and semi-structured data, enabling you to extract valuable insights and prepare data efficiently. SageMaker Data Wrangler now supports JSON format for both batch and real-time inference endpoint deployment.
Solution overview
For our use case, we use the sample Amazon customer reviews dataset to show how SageMaker Data Wrangler can simplify the operational effort to build a new ML model using SageMaker Autopilot. The Amazon customer reviews dataset contains product reviews and metadata from Amazon, including 142.8 million reviews spanning May 1996 to July 2014.
On a high level, we use SageMaker Data Wrangler to manage this large dataset and perform the following actions:
- Develop an ML model in SageMaker Autopilot using all of the dataset, not just a sample.
- Build a real-time inference pipeline with the inference artifact generated by SageMaker Data Wrangler, and use JSON formatting for input and output.
S3 manifest file support with SageMaker Autopilot
When creating a SageMaker Autopilot experiment using SageMaker Data Wrangler, you could previously only specify a single CSV or Parquet file. Now you can also use an S3 manifest file, allowing you to use large amounts of data for SageMaker Autopilot experiments. SageMaker Data Wrangler will automatically partition input data files into several smaller files and generate a manifest that can be used in a SageMaker Autopilot experiment to pull in all the data from the interactive session, not just a small sample.
Complete the following steps:
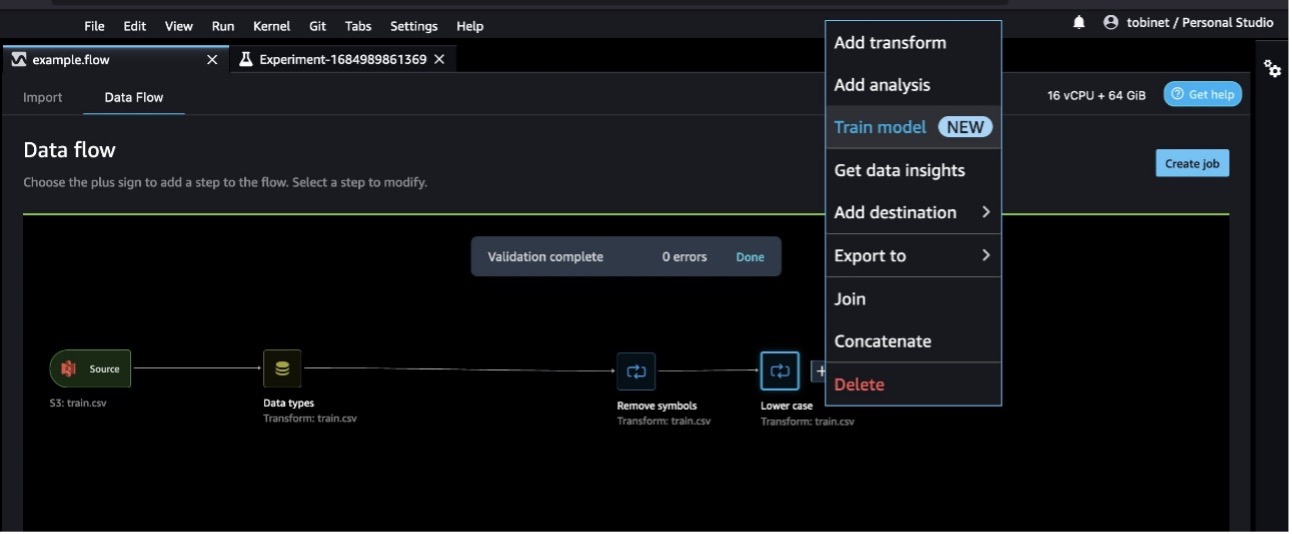
- Import the Amazon customer review data from a CSV file into SageMaker Data Wrangler. Make sure to disable sampling when importing the data.
- Specify the transformations that normalize the data. For this example, remove symbols and transform everything into lowercase using SageMaker Data Wrangler’s built-in transformations.
- Choose Train model to start training.
To train a model with SageMaker Autopilot, SageMaker automatically exports data to an S3 bucket. For large datasets like this one, it will automatically break up the file into smaller files and generate a manifest that includes the location of the smaller files.

- First, select your input data.
Earlier, SageMaker Data Wrangler didn’t have an option to generate a manifest file to use with SageMaker Autopilot. Today, with the release of manifest file support, SageMaker Data Wrangler will automatically export a manifest file to Amazon S3, pre-fill the S3 location of the SageMaker Autopilot training with the manifest file S3 location, and toggle the manifest file option to Yes. No work is necessary to generate or use the manifest file.

- Configure your experiment by selecting the target for the model to predict.
- Next, select a training method. In this case, we select Auto and let SageMaker Autopilot decide the best training method based on the dataset size.

- Specify the deployment settings.
- Finally, review the job configuration and submit the SageMaker Autopilot experiment for training. When SageMaker Autopilot completes the experiment, you can view the training results and explore the best model.

Thanks to support for manifest files, you can use your entire dataset for the SageMaker Autopilot experiment, not just a subset of your data.
For more information on using SageMaker Autopilot with SageMaker Data Wrangler, see Unified data preparation and model training with Amazon SageMaker Data Wrangler and Amazon SageMaker Autopilot.
Generate inference artifacts from SageMaker Processing jobs
Now, let’s look at how we can generate inference artifacts through both the SageMaker Data Wrangler UI and SageMaker Data Wrangler notebooks.
SageMaker Data Wrangler UI
For our use case, we want to process our data through the UI and then use the resulting data to train and deploy a model through the SageMaker console. Complete the following steps:
- Open the data flow your created in the preceding section.
- Choose the plus sign next to the last transform, choose Add destination, and choose Amazon S3. This will be where the processed data will be stored.

- Choose Create job.

- Select Generate inference artifacts in the Inference parameters section to generate an inference artifact.
- For Inference artifact name, enter the name of your inference artifact (with .tar.gz as the file extension).
- For Inference output node, enter the destination node corresponding to the transforms applied to your training data.
- Choose Configure job.

- Under Job configuration, enter a path for Flow file S3 location. A folder called
data_wrangler_flowswill be created under this location, and the inference artifact will be uploaded to this folder. To change the upload location, set a different S3 location. - Leave the defaults for all other options and choose Create to create the processing job.

The processing job will create atarball (.tar.gz)containing a modified data flow file with a newly added inference section that allows you to use it for inference. You need the S3 uniform resource identifier (URI) of the inference artifact to provide the artifact to a SageMaker model when deploying your inference solution. The URI will be in the form{Flow file S3 location}/data_wrangler_flows/{inference artifact name}.tar.gz. - If you didn’t note these values earlier, you can choose the link to the processing job to find the relevant details. In our example, the URI is
s3://sagemaker-us-east-1-43257985977/data_wrangler_flows/example-2023-05-30T12-20-18.tar.gz.
- Copy the value of Processing image; we need this URI when creating our model, too.

- We can now use this URI to create a SageMaker model on the SageMaker console, which we can later deploy to an endpoint or batch transform job.

- Under Model settings¸ enter a model name and specify your IAM role.
- For Container input options, select Provide model artifacts and inference image location.

- For Location of inference code image, enter the processing image URI.
- For Location of model artifacts, enter the inference artifact URI.
- Additionally, if your data has a target column that will be predicted by a trained ML model, specify the name of that column under Environment variables, with
INFERENCE_TARGET_COLUMN_NAMEas Key and the column name as Value.
- Finish creating your model by choosing Create model.

We now have a model that we can deploy to an endpoint or batch transform job.
SageMaker Data Wrangler notebooks
For a code-first approach to generate the inference artifact from a processing job, we can find the example code by choosing Export to on the node menu and choosing either Amazon S3, SageMaker Pipelines, or SageMaker Inference Pipeline. We choose SageMaker Inference Pipeline in this example.

In this notebook, there is a section titled Create Processor (this is identical in the SageMaker Pipelines notebook, but in the Amazon S3 notebook, the equivalent code will be under the Job Configurations section). At the bottom of this section is a configuration for our inference artifact called inference_params. It contains the same information that we saw in the UI, namely the inference artifact name and the inference output node. These values will be prepopulated but can be modified. There is additionally a parameter called use_inference_params, which needs to be set to True to use this configuration in the processing job.

Further down is a section titled Define Pipeline Steps, where the inference_params configuration is appended to a list of job arguments and passed into the definition for a SageMaker Data Wrangler processing step. In the Amazon S3 notebook, job_arguments is defined immediately after the Job Configurations section.

With these simple configurations, the processing job created by this notebook will generate an inference artifact in the same S3 location as our flow file (defined earlier in our notebook). We can programmatically determine this S3 location and use this artifact to create a SageMaker model using the SageMaker Python SDK, which is demonstrated in the SageMaker Inference Pipeline notebook.
The same approach can be applied to any Python code that creates a SageMaker Data Wrangler processing job.
JSON file format support for input and output during inference
It’s pretty common for websites and applications to use JSON as request/response for APIs so that the information is easy to parse by different programming languages.
Previously, after you had a trained model, you could only interact with it via CSV as an input format in a SageMaker Data Wrangler inference pipeline. Today, you can use JSON as an input and output format, providing more flexibility when interacting with SageMaker Data Wrangler inference containers.
To get started with using JSON for input and output in the inference pipeline notebook, complete the follow steps:
- Define a payload.
For each payload, the model is expecting a key named instances. The value is a list of objects, each being its own data point. The objects require a key called features, and the values should be the features of a single data point that are intended to be submitted to the model. Multiple data points can be submitted in a single request, up to a total size of 6 MB per request.
See the following code:
- Specify the
ContentTypeasapplication/json. - Provide data to the model and receive inference in JSON format.

See Common Data Formats for Inference for sample input and output JSON examples.
Clean up
When you are finished using SageMaker Data Wrangler, we recommend that you shut down the instance it runs on to avoid incurring additional charges. For instructions on how to shut down the SageMaker Data Wrangler app and associated instance, see Shut Down Data Wrangler.
Conclusion
SageMaker Data Wrangler’s new features, including support for S3 manifest files, inference capabilities, and JSON format integration, transform the operational experience of data preparation. These enhancements streamline data import, automate data transformations, and simplify working with JSON data. With these features, you can enhance your operational efficiency, reduce manual effort, and extract valuable insights from your data with ease. Embrace the power of SageMaker Data Wrangler’s new features and unlock the full potential of your data preparation workflows.
To get started with SageMaker Data Wrangler, check out the latest information on the SageMaker Data Wrangler product page.
About the authors
 Munish Dabra is a Principal Solutions Architect at Amazon Web Services (AWS). His current areas of focus are AI/ML and Observability. He has a strong background in designing and building scalable distributed systems. He enjoys helping customers innovate and transform their business in AWS. LinkedIn: /mdabra
Munish Dabra is a Principal Solutions Architect at Amazon Web Services (AWS). His current areas of focus are AI/ML and Observability. He has a strong background in designing and building scalable distributed systems. He enjoys helping customers innovate and transform their business in AWS. LinkedIn: /mdabra
 Patrick Lin is a Software Development Engineer with Amazon SageMaker Data Wrangler. He is committed to making Amazon SageMaker Data Wrangler the number one data preparation tool for productionized ML workflows. Outside of work, you can find him reading, listening to music, having conversations with friends, and serving at his church.
Patrick Lin is a Software Development Engineer with Amazon SageMaker Data Wrangler. He is committed to making Amazon SageMaker Data Wrangler the number one data preparation tool for productionized ML workflows. Outside of work, you can find him reading, listening to music, having conversations with friends, and serving at his church.
[ad_2]
Source link
Leave a Reply