
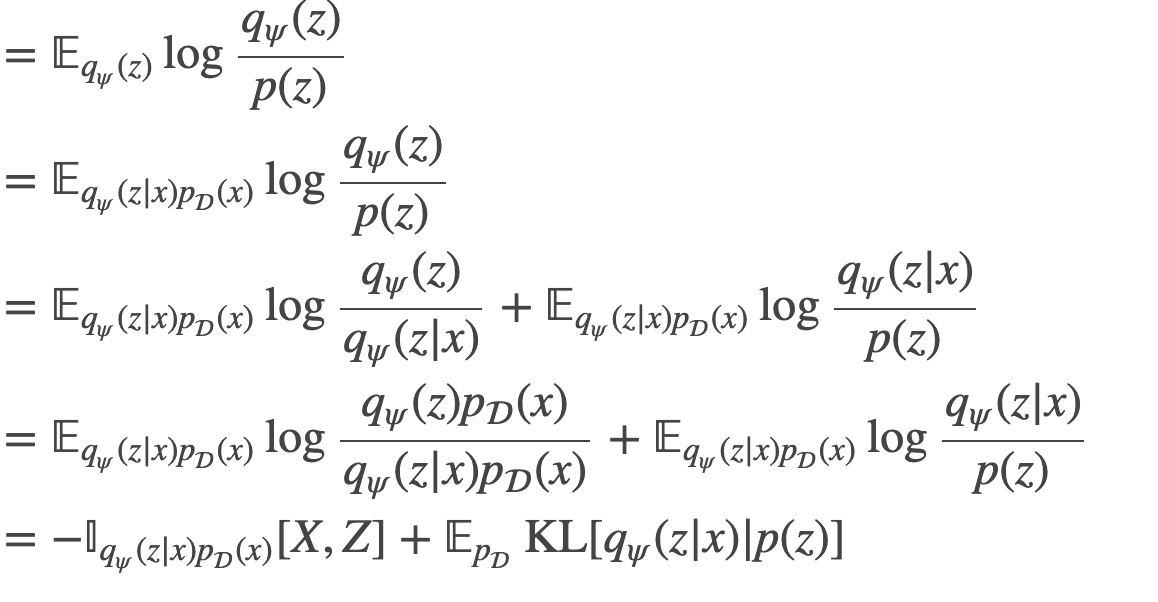
guest post with Dóra Jámbor
This is a half-guest-post written jointly with Dóra, a fellow participant in a reading group where we recently discussed the original paper on $beta$-VAEs:
On the surface of it, $beta$-VAEs are a straightforward extension of VAEs where we are allowed to directly control the tradeoff between the reconstruction and KL loss terms. In an attempt to better understand where the $beta$-VAE objective comes from, and to further motivate why it makes sense, here we derive $beta$-VAEs from different first principles than it is presented in the paper. Over to mostly Dóra for the rest of this post:
First, some notation:
- $p_mathcal{D}(mathbf{x})$: data distribution
- $q_psi(mathbf{z}vert mathbf{x})$: representation distribution
- $q_psi(mathbf{z}) = int p_mathcal{D}(mathbf{x})q_psi(mathbf{z}vert mathbf{x})$: aggregate posterior – marginal distribution of representation $Z$
- $q_psi(mathbf{x}vert mathbf{z}) = frac{q_psi(mathbf{z}vert mathbf{x})p_mathcal{D}(mathbf{x})}{q_psi(mathbf{z})}$: “inverted posterior”
Motivation and assumptions of $beta$-VAEs
Learning disentangled representations that recover the independent data generative factors has been a long-term goal for unsupervised representation learning.
$beta$-VAEs were introduced in 2017 with a proposed modification to the original VAE formulation that can achieve better disentanglement in the posterior $q_psi(mathbf{z}vert mathbf{x})$. An assumption of $beta$-VAEs is that there are two sets of latent factors, $mathbf{v}$ and $mathbf{w}$, that contribute to generating observations $x$ in the real world. One set, $mathbf{v}$, is coordinate-wise conditionally independent given the observed variable, i.e., $log p(mathbf{v}vert x) = sum_k log p(v_kvert mathbf{x})$. At the same time, we don’t assume anything about the remaining factors $mathbf{w}$.
The factors $v$ are going to be the main object of interest for us. The conditional independence assumption allows us to formulate what it means to disentangle these factors of variation. Consider a representation $mathbb{z}$ which entangles coordinates of $v$, in that each coordinate of $mathbb{z}$ depends on multiple coordinates of $mathbb{v}$, e.g. $z_1 = f_1(v_1, v_2)$ and $z_2 = f_2(v_1, v_2)$. Such a $mathbb{z}$ won’t necessarily satisfy co-ordinatewise conditional independence $log p(mathbf{z}vert x) = sum_k log p(z_kvert mathbf{x})$. However, if each component of $mathbb{z}$ depended only on one corresponding coordinate of $mathbf{v}$, for example $z_1 = g_1(v_1)$ and $z_2 = g_2(v_2)$, the component-wise conditional independence would hold for $mathbb{z}$ too.
Thus, under these assumptions we can encourage disentanglement to happen by encouraging the posterior $q_psi(mathbf{z}vert mathbf{x})$ to be coordinate-wise conditionally independent. This can be done by adding a new hyperparameter $beta$ to the original VAE formulation
$$
mathcal{L}(theta, phi; x, z, beta) = -mathbb{E}_{q_{phi}(xvert z)p_mathcal{D}(x)}[log p_{theta}(x vert z)] + beta operatorname{KL} (q_{phi(zvert x)}| p(z)),
$$
where $beta$ controls the trade-off between the capacity of the latent information channel and learning conditionally independent latent factors. When $beta$ is higher than 1, we encourage the posterior $q_psi(zvert x)$ to be close to the isotropic unit Gaussian $p(z) = mathcal{N}(0, I)$, which itself is coordnate-wise independent.
Marginal versus Conditional Independence
In this post, we revisit the conditional independence assumption of latent factors, and argue that a more appropriate objective would be to have marginal independence in the latent factors. To show you our intuition, let’s revisit the “Explaining Away” phenomenon from Probabilistic Graphical Models.
Explaining away
Consider three random variables:
$A$: Ferenc is grading exams
$B$: Ferenc is in a good mood
$C$: Ferenc is tweeting a meme
with the following graphical model $A rightarrow C leftarrow B$.
Here we could assume that Ferenc grading exams is independent of him being in a good mood, i.e., $A perp B$. However, the pressure of marking exams results in increased likelihood of procrastination, which increases the chances of tweeting memes, too.
However, as soon as we see a meme being tweeted by him, we know that he either in a good mood or he is grading exams. If we know he is grading exams, that explains why he is tweeting memes, so it’s less likely he’s tweeting memes because he’s a good mood. Consequently, $A not!perp Bvert C$.
In all seriousness, if we have a graphical model $A rightarrow C leftarrow B$, in evidence of $C$, independence between $A$ and $B$ no longer holds.
Why does this matter?
We argue that the explaining away phenomenon makes the conditional independence of latent factors undesirable. A much more reasonable assumption about the generative process of the data is that the factors of variation $mathbf{v}$ are drawn independently, and then the observations are generated conditoned on them. However, if we consider two coordinates of $mathbb{v}$ and the observation $mathbf{x}$, we now have a $V_1 rightarrow mathbf{X} leftarrow V_2$ graphical model, thus, conditional independence cannot hold.
Instead, we argue that to recover the generative factors of the data, we should encourage latent factors to be marginally independent. In the next section, we set out to derive an algorithm that encourages marginal independence in the representation Z. We will also show how the resulting loss function from this new derivation is actually equivalent to the original $beta$-VAEs formulation.
Marginally Independent Latent Factors
We’ll start from desired properties of the representation distribution $q_psi(zvert x)$. We’d like this representation to satisfy two properties:
- Marginal independence: We would like the aggregate posterior $q_psi(z)$ to be close to some fixed and factorized unit Gaussian prior $p(z) = prod_i p(z_i)$. This encourages $q_psi(z)$ to exhibit coordinate-wise independence.
- Maximum Information: We’d like the representation $Z$ to retain as much information as possible about the input data $X$.
Note that without (1), (2) is insufficient, because then any deterministic and invertible function of $X$ would contain maximum information about $X$ but that wouldn’t make it a useful or disentangled representation. Similarly, without (2), (1) is insufficient because if we set $q_psi(zvert x) = p(z)$ it would give us a latent representation Z that is coordinate-wise independent, but it is also independent of the data which is not very useful.
Deriving a practical objective
We can achieve a combination of these desiderata by optimizing an objective with the weighted combination of two terms corresponding to the two goals we set out above:
$$
mathcal{L}(psi) = operatorname{KL}[q_psi(z)| p(z)] – lambda mathbb{I}_{q_psi(zvert x) p_mathcal{D}(x)}[X, Z]
$$
Remember, we use $q_psi(z)$ to denote the aggregate posterior. We will refer to this as the InfoMax objective. Now we’re going to show how this objective can be related to the $beta$-VAE objective. Let’s first consider the KL term in the above objective:
begin{align}
operatorname{KL}[q_psi(z)| p(z)] &= mathbb{E}_{q_psi(z)} log frac{q_psi(z)}{p(z)}\
&= mathbb{E}_{q_psi(zvert x)p_mathcal{D}(x)} log frac{q_psi(z)}{p(z)}\
&= mathbb{E}_{q_psi(zvert x)p_mathcal{D}(x)} log frac{q_psi(z)}{q_psi(zvert x)} + mathbb{E}_{q_psi(zvert x)p_mathcal{D}(x)} log frac{q_psi(zvert x)}{p(z)}\
&= mathbb{E}_{q_psi(zvert x)p_mathcal{D}(x)} log frac{q_psi(z)p_mathcal{D}(x)}{q_psi(zvert x)p_mathcal{D}(x)} + mathbb{E}_{q_psi(zvert x)p_mathcal{D}(x)} log frac{q_psi(zvert x)}{p(z)}\
&= -mathbb{I}_{q_psi(zvert x)p_mathcal{D}(x)}[X,Z] + mathbb{E}_{p_mathcal{D}}operatorname{KL}[q_psi(zvert x)| p(z)]
end{align}
This is interesting. If the mutual information between $X$ and $Z$ is non-zero (which is ideally the case), the above equation shows that latent factors cannot be both marginally and conditionally independent at the same time. It also gives us a way to relate the KL terms representing marginal and conditional independence.
Putting this back into the InfoMax objective, we have that
begin{align}
mathcal{L}(psi) &= operatorname{KL}[q_psi(z)| p(z)] – lambda mathbb{I}_{q_psi(zvert x)p_mathcal{D}(x)}[X, Z]\
&= mathbb{E}_{p_mathcal{D}}operatorname{KL}[q_psi(zvert x)| p(z)] – (lambda + 1) mathbb{I}_{q_psi(zvert x)p_mathcal{D}(x)}[X, Z]
end{align}
Using the KL term in the InfoMax objective, we were able to recover the KL-divergence term that also appears in the $beta$-VAE (and consequently, VAE) objective.
At this point, we still haven’t defined the generative model $p_theta(xvert z)$, the above objective expresses everything in terms of the data distribution $p_mathcal{D}$ and the posterior/representation distribution $q_psi$.
We will now focus on the 2nd term in our desired objective, the weighted mutual information, which we still can’t easily evaluate. We will now show that we can recover the reconstruction term in $beta$-VAEs by doing a variational approximation to the mutual information.
Variational bound on mutual information
Note the following equality:
begin{equation}
mathbb{I}[X,Z] = mathbb{H}[X] – mathbb{H}[Xvert Z]
end{equation}
Since we sample X from the data distribution $p_mathcal{D}$, we see that the first term $mathbb{H}[X]$, the entropy of $X$, is constant with respect to the variational parameter $psi$. We are left to focus on finding a good approximation to the second term $mathbb{H}[Xvert Z]$. We can do so by minimizing the KL divergence between $q_psi(xvert z)$ and an auxilliary distribution $p_theta(xvert z)$ to make a variational appoximation to the mutual information:
$$mathbb{H}[Xvert Z] = – mathbb{E}_{qpsi(zvert x)p_mathcal{D}(x)} log q_psi(xvert z) leq inf_theta – mathbb{E}_{qpsi(zvert x)p_mathcal{D}(x)} log p_theta(xvert z)$$
Putting this bound back together:
Finding this lower bound to MI, we have now recovered the reconstruction term from the $beta$-VAE objective:
$$
mathcal{L}(psi) + text{const} leq – (1 + lambda) mathbb{E}_{q_psi(zvert x)p_mathcal{D}(x)} log p_theta(xvert z) + mathbb{E}_{p_mathcal{D}}operatorname{KL}[q_psi(zvert x)| p(z)]
$$
This is essentially the same as the $beta$-VAE objective function, where $beta$ is related to our previous $lambda$. In particular, $beta = frac{1}{1 + lambda}$. Thus, since we assumed $lambda>0$ for the InfoMax objective to make sense, we can say that the $beta$-VAE objective encourages disentanglement in the InfoMax sense for values of $0<beta<1$.
Takeaways
Conceptually, this derivation is interesting because the main object of interest is now the recognition model, $q_psi(zvert x)$. That is, the posterior becomes a the focus of the objective function – something that is not the case when we are maximizing model likelihood alone (as explained here). In this respect, this derivation of the $beta$-VAE makes more sense from a representation learning viewpoint than the derivation of VAE from maximum likelihood.
There is a nice symmetry to these two views. There are two joint distributions over latents and observable variables in a VAE. On one hand we have $q_psi(zvert x)p_mathcal{D}(x)$ and on the other we have $p(x)p_theta(xvert z)$. The “latent variable model” $q_psi(zvert x)p_mathcal{D}(x)$ is a family of LVMs which has a marginal distribution on observable $mathbf{x}$ that is exactly the same as the data distribution $p_mathcal{D}$. So one can say $q_psi(zvert x)p_mathcal{D}(x)$ is a parametric family of latent variable models with whose likelihood is maximal – and we want to choose from this family a model where the representation $q_psi(zvert x)$ has nice properties.
On the flipside, $p(z)p_theta(xvert z)$ is a parametic set of models where the marginal distribution of latents is coordinatewise independent, but we would like to choose from this family a model that has good data likelihood.
The VAE objective tries to move these two latent variable models closer to one another. From the perspective of $q_psi(zvert x)p_mathcal{D}(x)$ this amounts to reproducing the prior $p(z)$ with the aggregate posterior. from the perspective of $p(z)p_theta(xvert z)$, it amounts to maximising the data likelihood. When the $beta$-VAE objective is used, we additionally wish to maximise the mutual information between the observed data and the representation.
This dual role of information maximization and maximum likelihood has been pointed out before, for example in this paper about the IM algorithm. The symmetry of variational learning has been exploited a few times, for example in yin-yang machines, and more recently also in methods like adversarially learned inference.